日志系统架构与演进¶
我们可以打造以Loggie为核心的云原生可扩展的全链路数据平台,Loggie支持使用不同的技术选型。
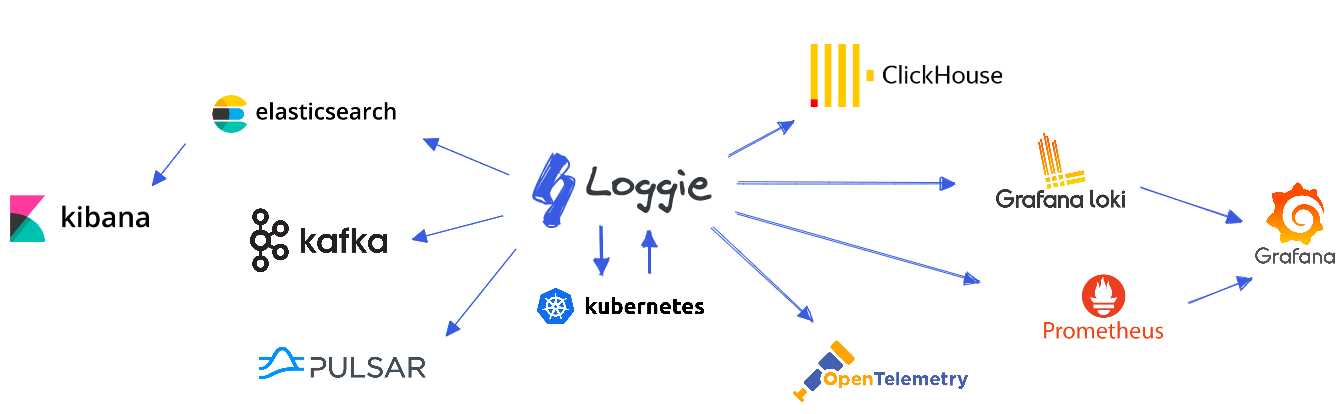
在不同的业务类型、不同的使用场景、不同的日志规模下,我们可能会采用不同的日志系统架构,架构不存在好坏,只有合不合适。一个简单的场景下,使用复杂的架构搭建出来的日志系统,大概会带来运维灾难。
这里通过规模演进的视角,总结一下常见的日志系统架构,当然实际的技术选型及变种有很多,我们无法一一列出,相信你可以通过参考下文,搭建适合自己业务的架构。
架构演进¶
需要提前说明的是:
- 下文的日志存储示例为Elasticsearch,消息队列为Kafka,具体选型请根据实际情况来做决定。
- 以下规模数据量只是作为一个参考值,具体的落地情况,还需要综合考虑更多因素,同时可以融合不同的选型,以达到最合适的架构。
小规模业务场景¶
每天的日志规模较小,比如只有几百G(预估500G以下)左右,日志的使用场景仅仅用于日常运维排查问题,可以采用Loggie直接发送至Elasticsearch集群的方式。
架构图如下所示:
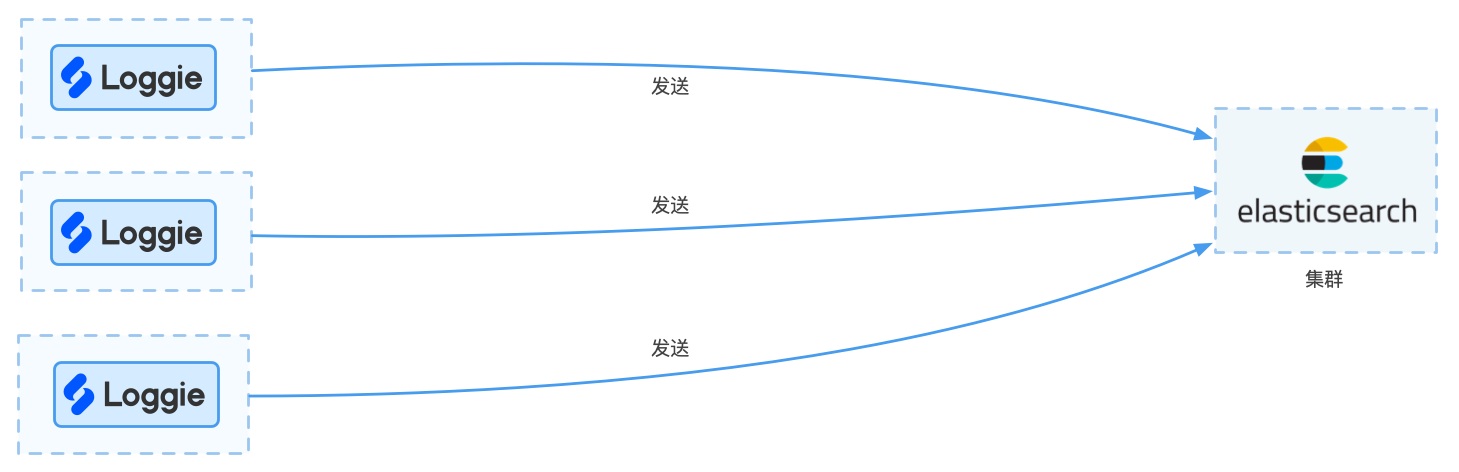
优点:
- 架构简单,便于维护
缺点:
- 由于Elasticsearch的性能有限,在日志量级突然增大时,Agent直接发送可能会导致大量的重试或者失败,导致Elasticsearch不稳定
- 可扩展性较差
变种:
因为一直以来ELK架构的流行,Elasticsearch是最常用的日志存储。
如果有其他服务对Elasticsearch的依赖,或者有Elasticsearch的运维经验,Elasticsearch是一个还不错的选择。
但是,Elasticsearch对资源和运维有一定的要求,在某些轻量级和资源敏感的环境下,可以考虑:
- 使用Loki存储
- 如果有相关的技术储备,还可以考虑发送至Clickhouse/Hive/Doris等。
中型规模业务场景¶
在每天的日志量级稍大,比如在500G至1T的规模,架构和业务使用上有扩展性的考虑,可考虑引入Loggie中转集群。
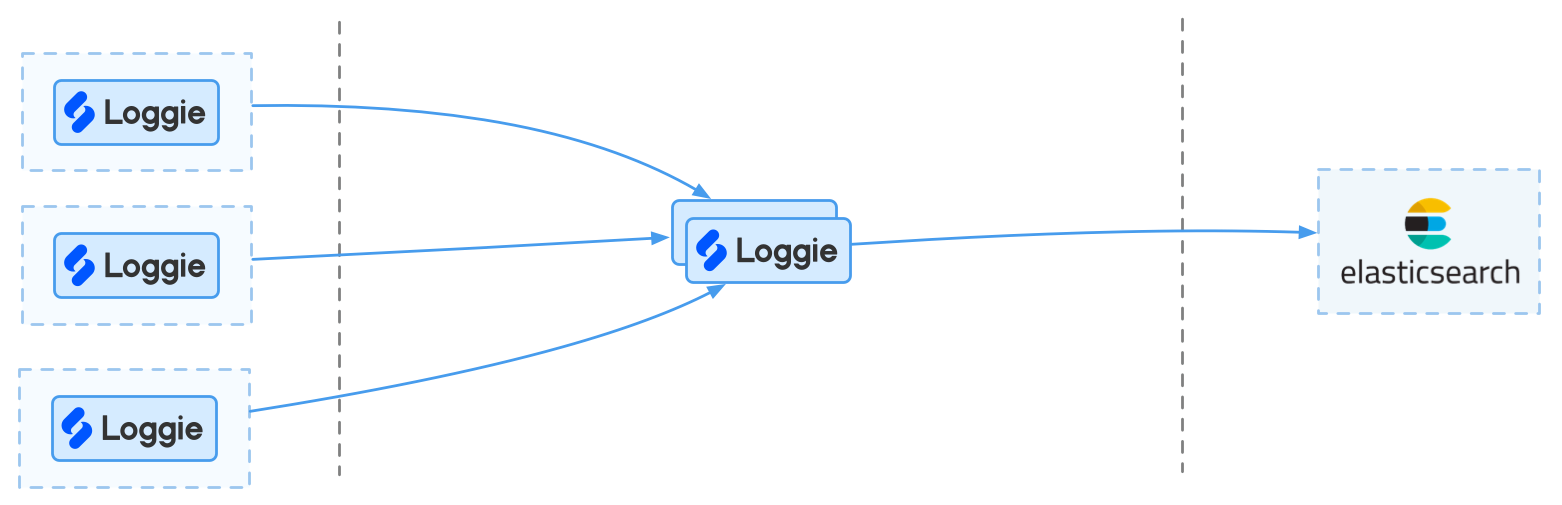
优点:
- 中转机集群可以承担日志切分等能力
- 中转机集群有一定的缓冲能力
缺点:
- 缓冲能力相比消息队列较弱
大型规模业务场景¶
如果日志量较大,比如1T以上场景,对性能与稳定性要求比较高,可考虑使用Kafka等消息队列集群。
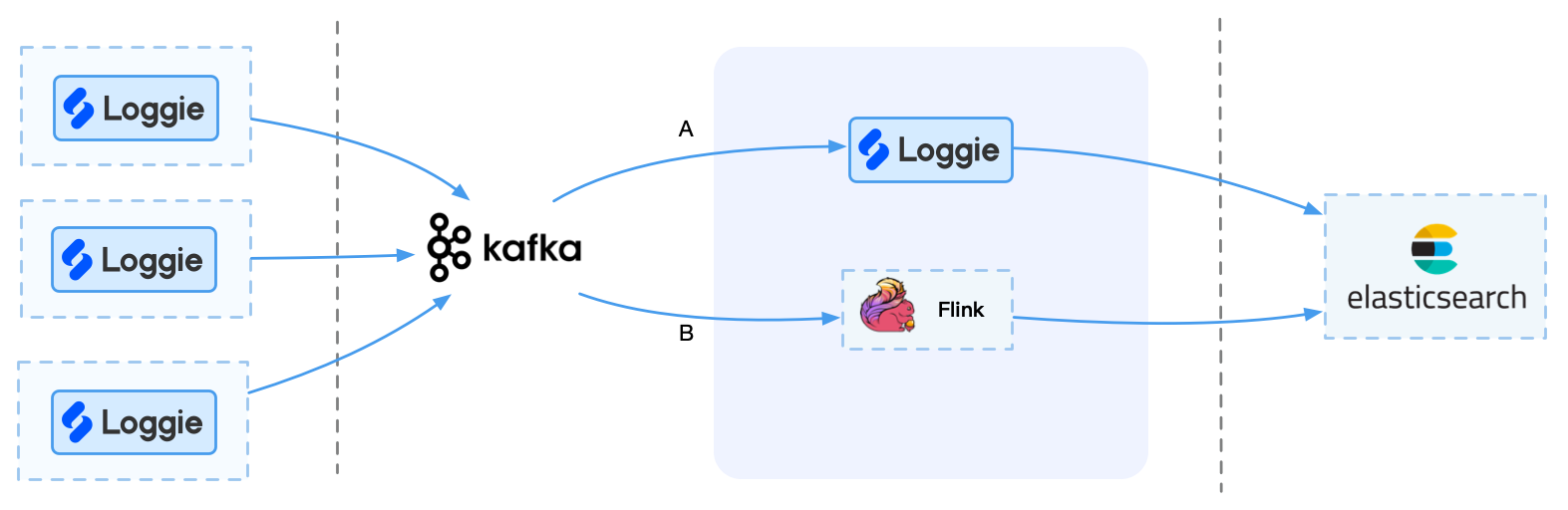
需要注意的是,Kafka本身并不能直接发送至后端,所以这里需要考虑如何将Kafka的数据实时导入到后端存储中。
这时候,我们可以选择一些组件消费Kafka,发送至后端,比如Loggie/Logstash/Kafka connect/Flink等。
但是Flink适合有自己的实时流平台或者运维能力的企业,否则可能引入更多运维成本。
优点:
- 使用消息队列比如Kafka,可以做到缓存和高峰期消峰
- 可以让更多的消费者消费Kafka,提供更多可扩展性
超大型规模业务场景¶
几十TB至PB级,相比上面大规模场景,集群数量多,机房架构复杂,可以根据以上架构增加更多灵活的扩展。
比如:
- 使用Loggie的多Pipeline特性,将业务日志拆分发送至多个Kafka集群
- 在大规模架构下增加前置Loggie中转集群,提前进行分流和转发
最终我们可以基于Loggie,搭建一套生产级别的全链路日志数据平台。
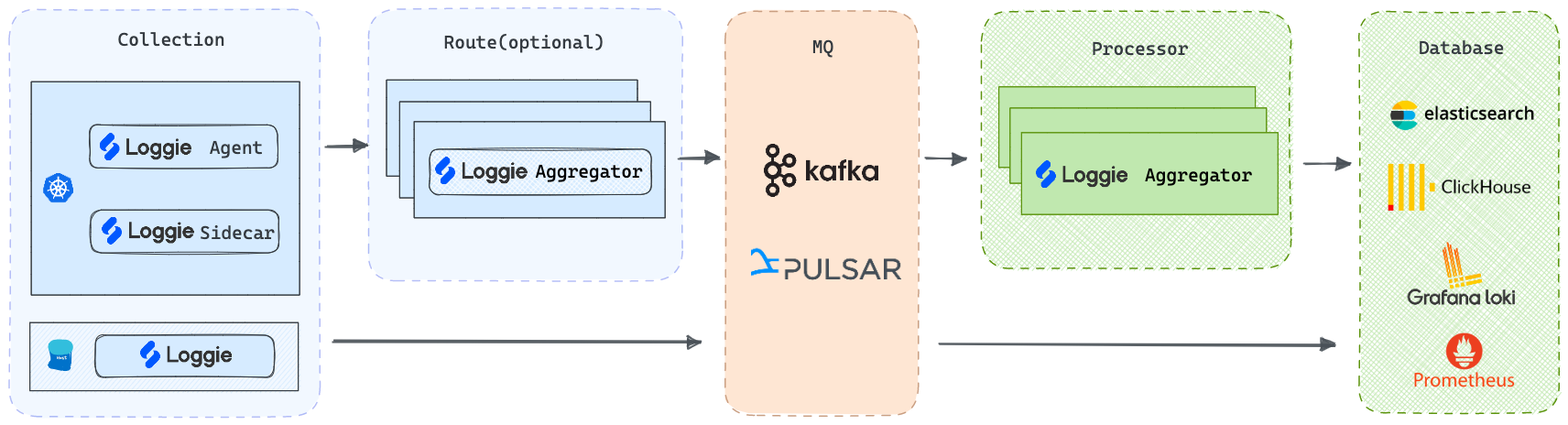
更多¶
实际在落地一套完善的日志架构和平台,还需要考虑:
- 可靠性:采集、传输、处理、查询整个链路需要保障尽量不丢日志,同时日志不影响业务稳定性
- 可观测性和可排障性:系统要有完善的监控指标,出现问题或者故障有快速排查的手段和方式,减少人力运维的成本
- 性能:采集、传输和处理需要轻量级,不占用太多资源,但是在数据量大的情况下,也需要有较低延迟和较大的吞吐量
- 易用性:日志采集配置使用方便,减少业务使用成本,同时不对应用的部署有侵入
- 功能完善:满足所需的日志处理、查询、监控报警等需求