Logging System Architecture and Evolution¶
Bases on different business types, different scenarios, and different log scales, we may adopt different log system architectures. There is no good or bad architecture, only suitable architecture. In a simple scenario, a log system built with a complex architecture may bring O&M disasters.
Here is a summary of common log system architectures from the perspective of scale evolution. Of course, there are many actual technical options and variants, and we cannot list them one by one. I believe you can build an architecture suitable for your own business by referring to the following.
Architecture Evolution¶
It should be noted in advance that:
- The following log storage example is Elasticsearch, and the message queue is Kafka. The specific selection should be determined according to the actual situation.
- The following scale data volume is only a reference value. More factors need to be comprehensively considered for the specific implementation situation. At the same time, different selections can be integrated to achieve the most suitable architecture.
Small-scale Business Scenarios¶
The daily log scale is small, for example, only about a few hundred gigabytes (estimated below 500G). The scenario of the log is only used for daily operation and maintenance troubleshooting. Loggie can be used to send log directly to the Elasticsearch cluster. The architecture diagram is shown below:
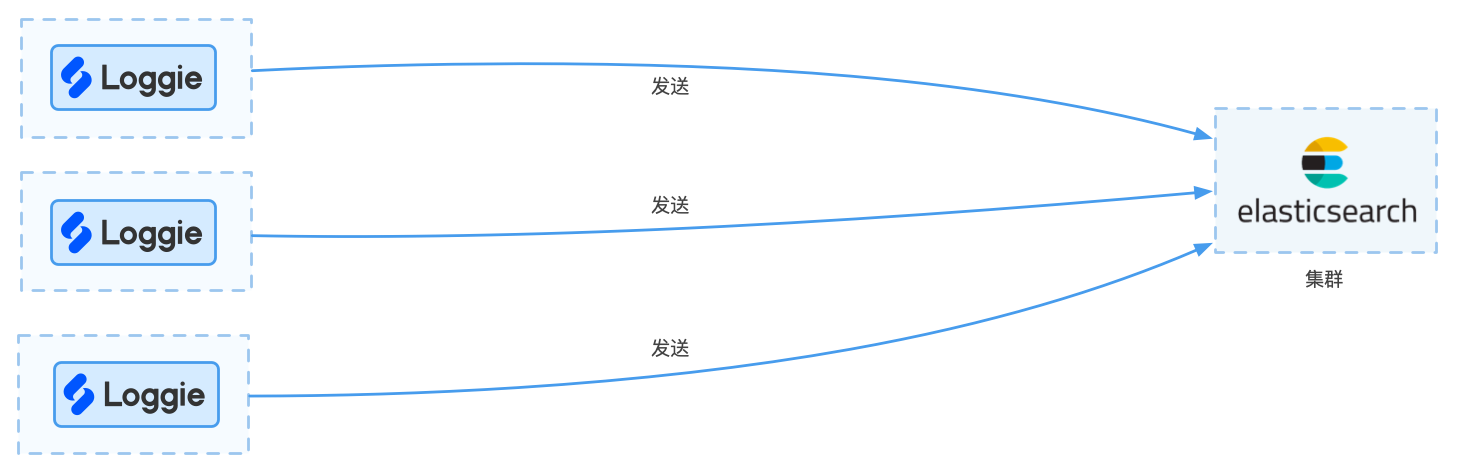
advantage:
- Simple structure and easy maintenance
disadvantage:
- Due to the limited performance of Elasticsearch, when the log amount suddenly increases, the direct sending of the agent may cause a large number of retries or failures, resulting in the instability of Elasticsearch
- Poor scalability
Variant:
Elasticsearch is the most commonly used log store due to the popularity of the ELK architecture.
If there are other services that depend on Elasticsearch, or if you have experience in the operation and maintenance of Elasticsearch, Elasticsearch is a good choice.
However, Elasticsearch has certain requirements on resources and operation and maintenance. In some lightweight and resource-sensitive environments, you can consider:
- Store with Loki
- If you have relevant technical resources, you can also consider sending log to Clickhouse/Hive/Doris, etc.
Medium-scale business scenarios¶
When the daily log level is slightly larger, for example, 500G to 1T, and there are considerations in scalability in terms of architecture and business use, the introduction of a Loggie Aggregator cluster can be considered.
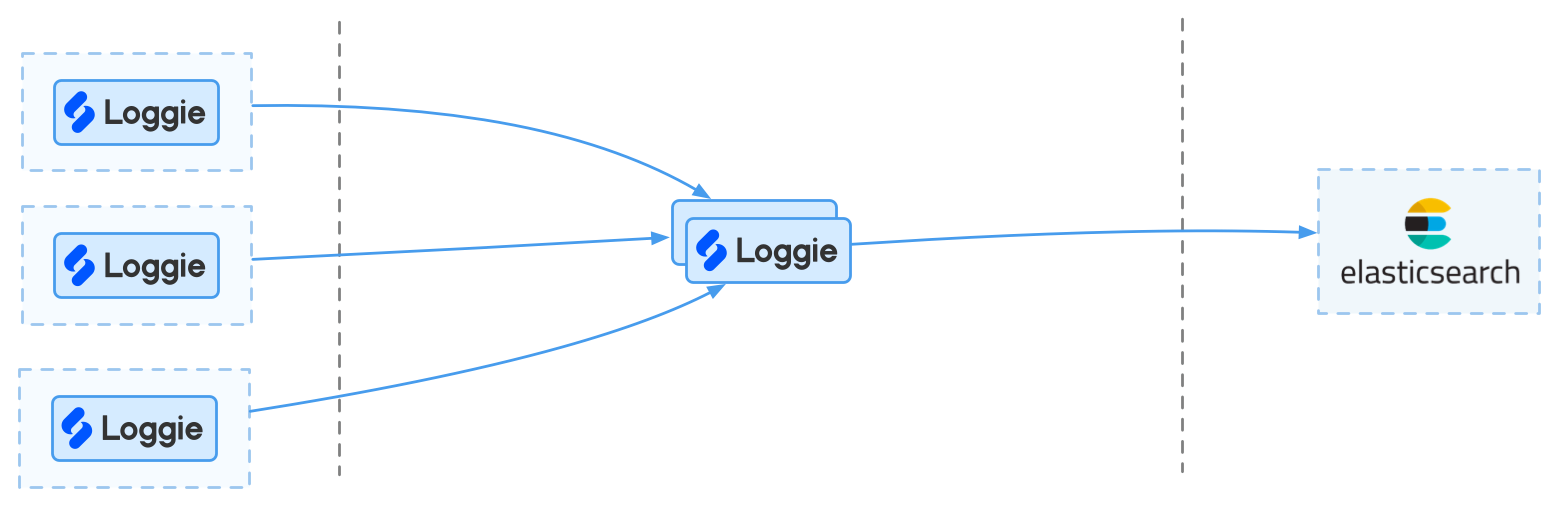
advantage:
- The aggregator cluster can undertake log segmentation and other capabilities.
- The aggregator cluster has a certain buffer capacity
disadvantage:
- The buffering capacity is weaker than the message queue.
Large-scale business scenarios¶
If the log volume is large (more than 1T) and the performance and stability are required, you can consider using a message queue cluster such as Kafka.
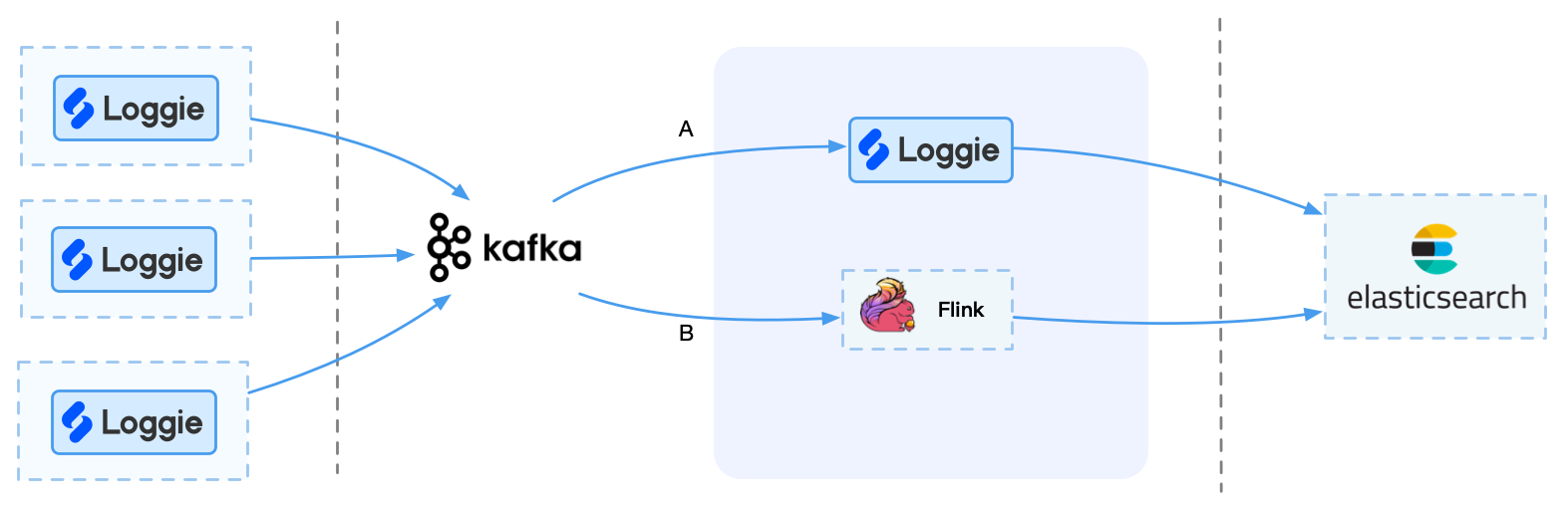
It should be noted that Kafka itself cannot directly send data to the backend, so it is necessary to consider how to import Kafka data into the backend storage in real time. At this time, we can choose some components to consume Kafka and send data to the backend, such as Loggie/Logstash/Kafka connect/Flink, etc. However, Flink is suitable for enterprises with their own real-time streaming platform or operation and maintenance capabilities, otherwise it may introduce more operation and maintenance costs.
advantage:
- Using message queues such as Kafka, you can realize caching and peak reduction.
- Allows more consumers to consume Kafka, providing more scalability
Ultra-large-scale business scenarios¶
Dozens of TB to PB level. Compared with the above large-scale scenarios, the number of clusters is larger, and the architecture is more complex. More flexible extension can be added according to the above architecture.
For example:
- Use Loggie's multi-pipeline feature to split business logs and send them to multiple Kafka clusters.
- Add a front-end Loggie aggregator cluster in a large-scale architecture, and perform traffic distribution and forwarding in advance.
More¶
In fact, in order to implement a complete log architecture, you also need to consider:
- Reliable: The entire link of collection, transmission, processing, and query needs to ensure that logs are not lost as much as possible, and that logs do not affect business stability.
- Observable and easy to troubleshoot: The system must have complete monitoring indicators, and there must be quick troubleshooting methods for problems or failures to reduce the cost of human operation and maintenance.
- Good performance: Collection, transmission and processing need to be lightweight and do not take up too many resources. And in the case of large data volumes, low latency and high throughput are also required.
- Easy to use: Log collection is easy to configure, reducing business usage costs. Do not intrude on application deployment.
- Complete: Meet the requirements of log processing, querying, monitoring and alarming, etc.